最近我在调整一个静态站点的部署方式。
原来的做法很常见:内容仓库一有更新,就让外部 CI 连接生产服务器,拉代码、构建、发布。这个方案能跑,也不算罕见,但它有一个让我不太舒服的地方:主动权在外部 runner 手里,服务器只是被动接受一次远程操作。
后来我把它反过来了。生产服务器自己定时检查站点代码和内容仓库,没变化就什么都不做;有新版本,就拉取、构建、发布;成功或失败,再把结果发到消息渠道。
这件事本身并不复杂。真正值得讨论的是它背后的问题:
高频定时任务触发时,到底要不要每次都唤醒 Agent?
我现在的判断是:高频、确定性、绝大多数时候没有变化的任务,不应该每次都先叫醒 Agent。更合理的方式是先让脚本判断事实,只有发生值得人看的事件时,再让 Agent 负责解释和通知。
换句话说,关键不是让 Agent 更勤快,而是把 Agent 的出场时机后移。
先看同一个任务
为了避免讨论变成抽象概念,先固定一个具体任务:每 5 分钟检查一次静态站点是否需要部署。
这个任务要做的事情很明确:检查远端仓库有没有新 commit,必要时拉取代码,执行构建,把构建结果发布到线上目录,然后做一次健康检查。大多数时候,它什么都不会部署,因为没有新版本。少数时候,它会成功发布。更少数时候,它会失败,需要人看日志。
这类任务最有意思的地方在于频率。每 5 分钟一次,一天就是 288 次。如果每天真正有变化的只有两三次,那么剩下 280 多次都是“确认没事”。这时候,系统设计的重点就不是“能不能处理复杂问题”,而是“能不能用很低的成本确认没有事情发生”。
把这个任务放到不同定时任务机制里,差异就出来了。
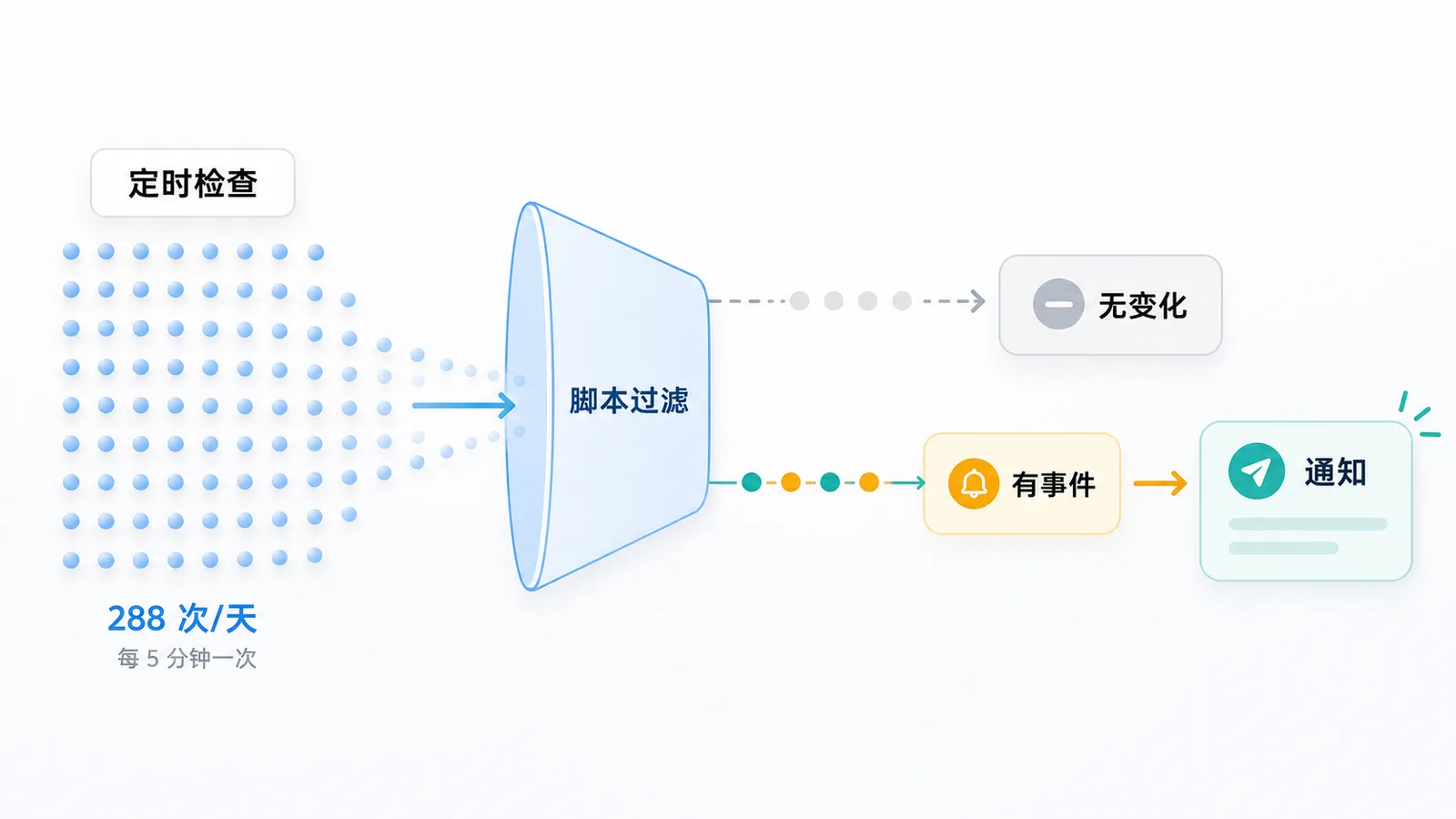
Agent cron:先叫醒 Agent
第一种模式是 Agent-first 的定时任务:cron 到点,先唤醒 Agent,由 Agent 判断接下来要做什么。
这很适合开放问题。比如每天整理信息源、每周分析项目状态、定期检查邮件并判断优先级。这些任务的难点不在执行某个命令,而在理解信息、做取舍、形成一个能给人看的判断。Agent 直接接管,反而自然。
但部署检查不是这种问题。
部署有没有发生,构建有没有失败,线上页面是否能访问,都是确定性信号。它们可以由 commit hash、退出码、状态文件、HTTP 状态码和构建日志来判断。让 Agent 每 5 分钟醒来一次,再去确认这些硬信号,多数时候只是把一个简单判断变贵了。
这不是 Agent 能不能做的问题,而是值不值得。高频检查最需要的能力不是“思考”,而是便宜、稳定、安静地确认“没事”。
command cron:脚本先跑,但脚本也要自己收尾
OpenClaw 的 command cron 往这个方向走了一步。它不像 Agent cron 那样每次先启动 Agent,而是到点直接执行 command 或 script。
放到部署任务里,它大概是这样:
每 5 分钟执行部署检查脚本
-> 没有新版本:输出 NO_REPLY
-> 有新版本:构建并输出结果
-> 构建失败:输出错误信息这已经适合很多高频任务。磁盘空间检查、HTTP 健康检查、备份结果、队列长度监控,都可以这么做。脚本能给出清楚结果时,不需要 Agent 参与。
但 command cron 的边界也在这里:它本质上还是脚本任务。脚本输出什么,通知里大概率就是什么。如果脚本写得很克制,通知就干净;如果脚本把最近 100 行日志直接吐出来,消息渠道里看到的就是 100 行日志。
当然,可以在脚本里自己再编排一步:发现部署失败后,调用 Agent API,让 Agent 读日志、写摘要、生成通知。这条路能跑,也不难理解。但这已经是用户自己把“脚本过滤”和“Agent 总结”拼起来了,不是 command cron 这个抽象默认帮你表达的流程。
所以我说它解决了一半问题:它解决了“不要每次都用 Agent 执行”,但没有完整解决“什么时候应该让 Agent 参与,以及让 Agent 参与后该做什么”。
Hermes:脚本先判断,Agent 后解释
Hermes 让我觉得顺手的地方,是它把这个二段式流程变成了定时任务的正常形态。
脚本先跑,负责拿事实、做判断、给出 gate。没有新版本,就明确告诉系统这次不用唤醒 Agent;有新部署、有失败、有异常,再把结构化结果交给 Agent。
放到部署任务里,脚本负责回答这些问题:
- 有没有新 commit?
- 构建命令退出码是多少?
- 发布前后的版本分别是什么?
- 健康检查是否通过?
- 如果失败,最近的关键日志是什么?
Agent 不再负责猜“到底有没有部署成功”。它看到的是脚本已经确认过的事实,然后把这些事实压缩成一条人能读懂的通知。
比如成功时,通知只需要告诉你:这次确实发布了,站点代码和内容版本分别是什么,构建是否通过,线上健康检查是否正常。失败时,通知也不应该把整段日志搬过来,而是说明失败发生在哪一步、脚本拿到的错误是什么、下一步应该先看哪里。
这里的边界很清楚:
脚本负责事实
Agent 负责表达我认为这个分工比“所有事情都交给 Agent”更健康。确定性问题应该由确定性工具判断,Agent 更适合做信息压缩、解释和面向人的沟通。
三种模式真正差在哪
如果只看“到点执行”,OpenClaw command cron 和 Hermes script-gated cron 看起来很像,都是先跑脚本。但如果把它放进 Agent 自动化系统里看,差别就比较明显。
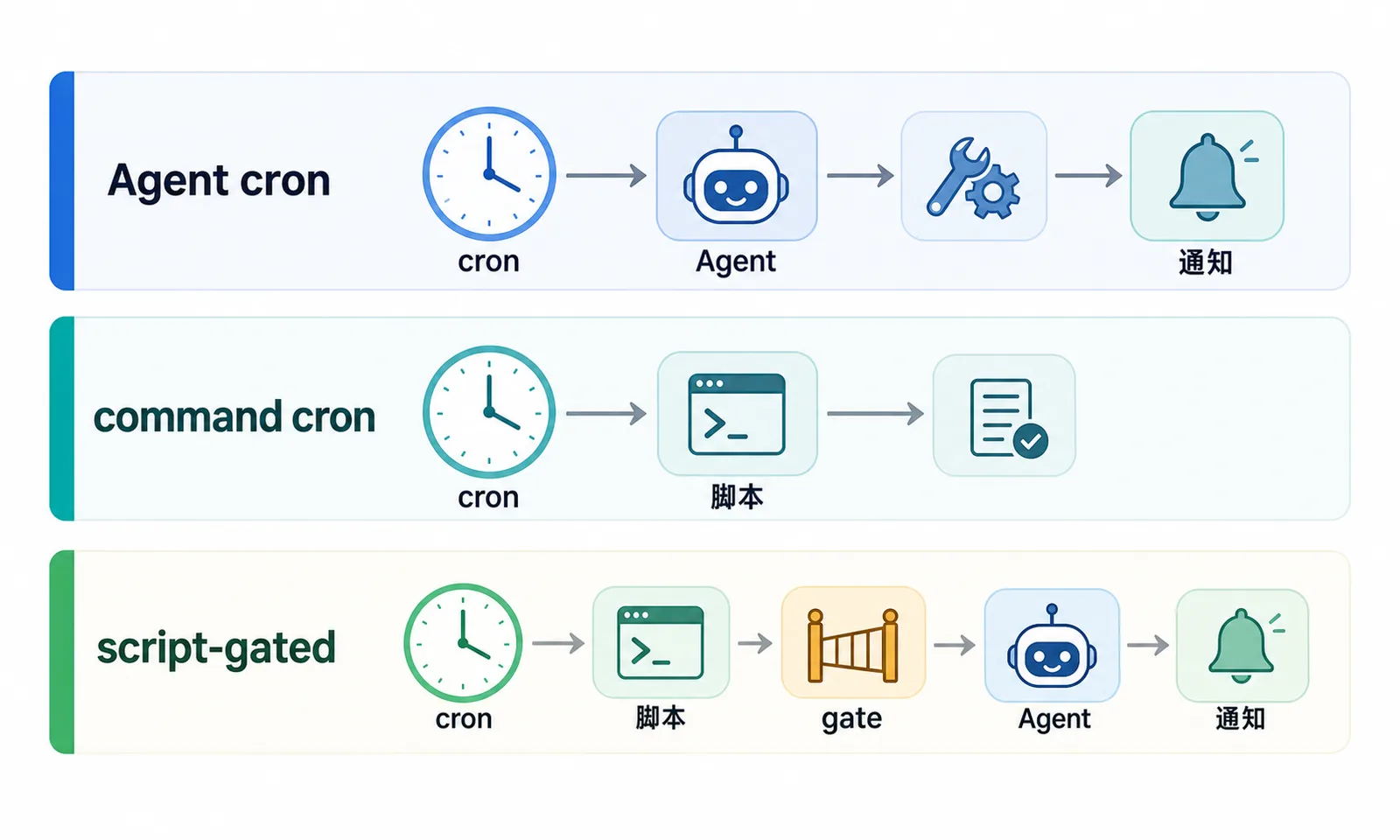
| 模式 | 谁先出场 | 适合什么任务 | 没变化时的成本 |
|---|---|---|---|
| Agent cron | Agent | 信息整理、判断、研究、周报 | 每次都要唤醒 Agent |
| command cron | 脚本 | 纯检查、纯执行、纯通知 | 只跑脚本 |
| script-gated cron | 脚本,必要时 Agent | 高频检查 + 需要人读懂结果 | 没事只跑脚本,有事再唤醒 Agent |
这张表里最关键的不是产品名字,而是“谁先判断事实”。
如果一个任务的事实本身就不确定,比如“今天哪些信息值得我看”,那 Agent 应该先出场。因为你要的就是它的理解和判断。
如果一个任务的事实很确定,比如“磁盘是不是超过 85%”,脚本就够了。Agent 参与反而多了一层不确定性。
如果一个任务的执行过程很确定,但结果需要讲给人听,比如部署、同步、RSS 变化、价格监控、Git 变更检测,那我更喜欢 script-gated cron。平时安静,出事时让 Agent 把事实讲清楚。
不要把脚本层神化
不过,脚本先判断并不意味着脚本可以随便写。
一旦脚本变成事实来源,脚本写错,Agent 只会把错误事实讲得更顺。部署脚本、备份脚本、健康检查脚本经常碰到密钥、生产目录、权限和网络失败,不能因为后面有 Agent 总结,就放松对脚本本身的要求。
我会特别关注几件事。
第一,状态要有锚点。比如部署任务最好记录站点代码版本、内容版本、上次部署时间和健康检查结果,而不是从一段日志里猜“这次有没有部署”。
第二,脚本要有明确退出语义。成功、无变化、失败、部分成功,最好能区分清楚。否则 Agent 拿到的只是含糊的文本,它再会总结,也无法补上事实缺口。
第三,通知 prompt 要克制。Agent 只能总结脚本提供的事实,没有证据就说没有证据,不要硬编根因。它可以给排查方向,但不能把猜测写成结论。
这些约束看起来琐碎,但它们决定了这种模式能不能长期运行。一个好的 script-gated cron,不是“脚本随便跑,Agent 帮忙润色”,而是脚本把事实边界收紧,Agent 把沟通成本降下来。
我的结论
所以,比较 OpenClaw 和 Hermes 的定时任务机制,只是一个入口。我真正关心的是另一个更通用的问题:Agent 自动化里,脚本和 Agent 应该怎么分工。
我的答案是:确定性判断尽量交给脚本,开放性理解交给 Agent;高频任务先让脚本过滤,只有发生有意义事件时,再让 Agent 出场。
对低频、开放、需要判断的任务,Agent cron 很自然。对纯检查、纯执行的任务,command cron 已经足够。对高频、确定性、但结果需要人读懂的任务,我更偏向 Hermes 这种 script-gated cron。
这样设计之后,token 消耗不再按“触发次数”算,而是按“有意义事件”算。系统也不会因为定时任务很多,就不断制造“正常运行”的噪音。
真正好的 Agent 自动化,不是让 Agent 永远在线,而是让它在该出现的时候出现。